اینجا من سعی کردم به زبون ساده نوشتهِ ایشون رو ترجمه کنم.
برای خوندن این نوشتهِ به زبان اصلی میتونید به آدرس وبلاگ ایشون مراجعه کنید یا برای خوندن ادامه ترجمه، روی دکمه «ادامه مطلب» کلیک کنید:
شبکههای عصبی بازگشتی (RNN)
در مورد نحوه فکر کردن انسانها میشه گفت اینجوری نیست که هر ثانیه ریست بشن و روند فکر کردن از اول شروع بشه. در همین لحظه که دارید این مطلب رو میخونید شما معنی هر کلمه رو با توجه به دانشی که از خوندن کلمههای قبلی کسب کردید متوجه میشید. به عبارتی شما موقع خوندن یک متن، درک و فهمی رو که در مورد اون متن با توجه به خوندن کلمات قبل کسب کردید دور نمیریزید بلکه به صورت پیوسته با خوندن هر کلمه جدید، نسبت به اون متنی که دارید میخونید درک و فهم پیدا میکنید و به عبارتی معنی اون متن رو متوجه میشید.
شبکههای عصبی متداولی که تاکنون متخصصان یادگیری ماشین از اونها استفاده میکردن نمیتونستن به این صورت شبیه انسان عمل کنند و این یک نقصان بزرگ برای این شبکهها محسوب میشه. برای مثال فرض کنید مدلی که شما ساختید قرار است مشخص کند در هر لحظه از فیلم چه اتفاقی در حال افتادن است. مشخص نیست شبکههای عصبی قدیمی چطور میتوانند از اطلاعاتی که در صحنههای قبلی فیلم به دست آوردهاند برای تشخیص نوع اتفاق در صحنههای بعدی فیلم استفاده کنند.
شبکههای عصبی بازگشتی (Recurrent Neural Network) برای برطرف کردن این مشکل طراحی شدند. در حقیقت شبکههای عصبی بازگشتی تو خودشون شامل یه حلقه بازگشتی هستند که منجر میشه اطلاعاتی که از لحظات قبلی بدست آوردیم از بین نرن و تو شبکه باقی بمونن.

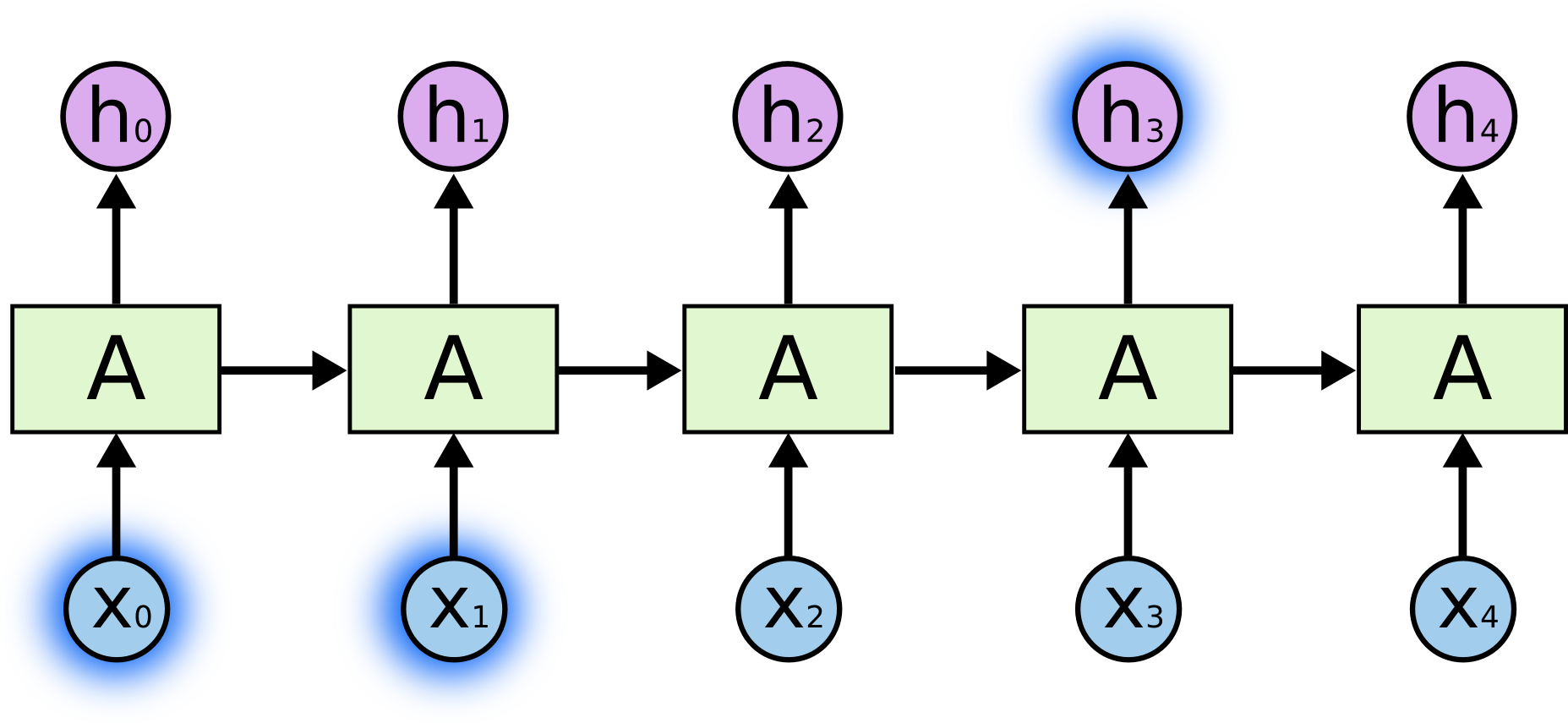
شبکههای عصبی بازگشتی دارای حلقه هستند.
در شکل بالا، بخش A، به عنوان ورودی مقدار xt را دریافت و مقدار ht را به خروجی میبرد. حلقه باعث میشود که اطلاعات از یک مرحله به مرحله بعد ارسال شوند.
این حلقهها احتمالا باعث شدن که شبکههای عصبی بازگشتی براتون مبهم به نظر بیان. اگر چه اگه بیشتر جلو بریم متوجه میشید که این شبکهها عملاً تفاوت خاصی با شبکههای عصبی معمولی ندارن. شبکههای عصبی بازگشتی رو میشه به صورت چندین کپیِ یکسان از یک شبکه عصبی در نظر گرفت که هر کدام اطلاعاتش را به شبکه بعدی منتقل میکند. در شکل زیر وضعیت شبکه عصبی بازگشتی در صورت باز کردن حلقه نمایش داده شده است:

شبکه عصبی بازگشتیِ باز شده
با توجه به ذات زنجیرهمانند شبکههای عصبی بازگشتی، میتوان تشخیص داد که این شبکهها به مقدار زیادی به دنبالهها و لیستها مرتبط هستند. در حقیقت شبکههای عصبی بازگشتی اولین انتخاب برای کار با چنین دادههایی هستند.
در حقیقت در سالهای گذشته مکرراً از این شبکهها استفاده شده که منجر به موفقیتهای بسیار چشمگیری در حوزههای مختلف از جمله تشخیص صدا، مدل کردن زبان، ترجمه، درج خودکار توضیح برای تصویر و ... شده است. برای مشاهده نتایج و آزمایشات خارقالعادهای که با اساتفاده از شبکههای عصبی بازگشتی انجام شده، میتوانید نوشتهِ جذاب و عالی Andrej Karpathy با عنوان عملکرد عالی ولی بیدلیل شبکههای عصبی بازگشتی رو مطالعه کنید که قدرت خارقالعاده شبکههای عصبی بازگشتی شرح داده شده.
بیشتر این موفقیتها مدیون استفاده از شبکههای "LSTM" است. نوع خاصی از شبکههای عصبی بازگشتی که در بیشتر موارد عملکرد بهتری از شبکههای عصبی بازگشتی استاندارد دارد. تقریباً میشه گفت اکثر موفقیتهای شبکههای عصبی بازگشتی وقتی بدست آمده که از LSTMها استفاده شده است. تو این نوشته ما شبکههای LSTM رو به تفسیر توضیح میدیم.
مشکلی به نام وابستگیهای بلندمدت
یکی از جذابیتهای شبکههای عصبی بازگشتی این است که آنها ممکن است بتوانند اطلاعات که قبلاً مشاهده شده را به کاری که در حال حاضر در حال انجام است مرتبط سازد، برای مثال استفاده از فریمهای قبلی یک ویدئو میتواند در فهمیدن فریم کنونی کمککننده باشد. اگر شبکههای عصبی بازگشتی بتوانند واقعاً این کار را انجام دهند، میتوان آنها را بسیار مفید دانست. ولی آیا واقعاً میتونن؟ جواب اینه که بستگی داره.
بعضی مواقع ما فقط نیاز داریم فقط به اطلاعات گذشته نزدیک نگاه کنیم تا متوجه اطلاعات حال حاضر بشیم. برای مثال، فرض کنید ما مدلِ زبانیای ساختهایم که تلاش میکند کلمه بعدی را با توجه به کلمات قبلیای که در اختیارش قرار دادیم پیشبینی کند. اگه ما میخوایم آخرین کلمه تو جمله «ابرها هستند در آسمان» رو پیشبینی کنیم، ما به اطلاعات اضافیِ دیگهای نیاز نداریم و تقریباً میشه گفت واضحه که کلمه بعدی «آسمان» است. در موارد مشابه این مثال، که فاصله بین اطلاعات مرتبط و جایی که به این اطلاعات نیاز داریم خیلی کمه، شبکههای عصبی بازگشتی میتونن یاد بگیرن که از این اطلاعات استفاده کنند.
ولی ممکن است مواردی وجود داشته باشد که ما به اطلاعات بیشتری نیاز داشته باشیم. فرض کنید قصد داریم کلمه بعدی در جمله «من زبان فرانسه را خیلی راحت صحبت میکنم... من به دنیا آمدم در فرانسه.» با توجه به اطلاعات اخیر (یعنی چهار پنج کلمه قبل از آخرین کلمه)، میتوان گفت که کلمه آخر احتمالا اسم یک کشور است، ولی اگر بخواهیم دقیقاً متوجه بشیم چه کشوری است، ما نیاز داریم به اطلاعات دورتر (یعنی تا ده یا بیست کلمه قبل از آخرین کلمه) دسترسی داشته باشیم. به صورت کلی ممکن است فاصله بین اطلاعات مرتبط و جایی که به این اطلاعات نیاز داریم زیاد باشد.
متأسفانه، هر چه این فاصله افزایش پیدا میکند، شبکههای عصبی بازگشتی قدرتشان را در به یادآوردن و استفاده از اطلاعاتی که در گذشته دورتر یاد گرفتهاند کاهش پیدا میکند و به عبارتی توانائی استفاده از اطلاعات گذشته دورتر را ندارند.

از نظر تئوری، شبکههای عصبی بازگشتی توانائی مدیریت وابستگیهای بلندمدت رو باید داشته باشند. یک فرد متخصص میتونه با دقت پارامترهای شبکه رو طوری تعیین کنه که مسائل کوچیکِ این شکلی را حل کنه. متأسفانه در عمل شبکههای عصبی بازگشتی توانائی یادگیری وابستگی بلندمدت رو ندارن. این مشکل به صورت دقیقتر تو این دو تا مقاله یعنی Hochreiter 1991 و Bengio, et al. 1994 شرح داده شدن.
بخوام خلاصه بگم دو تا مشکل اصلی به نام Vanishing and Exploding Gradient تو شبکههای عصبی بازگشتی وجود داره که LSTM حلاش کرده که میتونید خودتون در موردشون بیشتر تحقیق کنید. (این پاراگراف تو متن اصلی نیست!)
خُب خوشبختانه، شبکههای LSTM این مشکل را حل کردهاند!
شبکههای LSTM
شبکههای LSTM که خلاصه شده عبارت "Long Short Term Memory" هستند، نوع خاصی از شبکههای عصبی بازگشتی هستند که توانائی یادگیری وابستگیهای بلندمدت را دارند. این شبکهها برای اولین بار توسط Hochreiter و Schmidhuber در سال ۱۹۹۷ در این مقاله معرفی شدند. البته تعداد زیادی از محققان در بهبود این شبکهها نقش داشتند که در متن اصلی به آنها اشاره شده است.
در حقیقت هدف از طراحی شبکههای LSTM، حل کردن مشکل وابستگی بلندمدت بود. به این نکته مهم توجه کنید که به یاد سپاری اطلاعات برای بازههای زمانی بلند مدت، رفتار پیشفرض و عادی شبکههای LSTM است و ساختار آنها به صورتی است که اطلاعات خیلی دور را به خوبی یاد میگیرند که این ویژگی در ساختار آنها نهفته است.
همه شبکههای عصبی بازگشتی به شکل دنبالهای (زنجیرهای) تکرار شونده از ماژولهای (واحدهای) شبکههای عصبی هستند. در شبکههای عصبی بازگشتی استاندارد، این ماژولهای تکرار شونده ساختار سادهای دارند، برای مثال تنها شامل یک لایه تانژانتِ هایپربولیک (tanh) هستند.
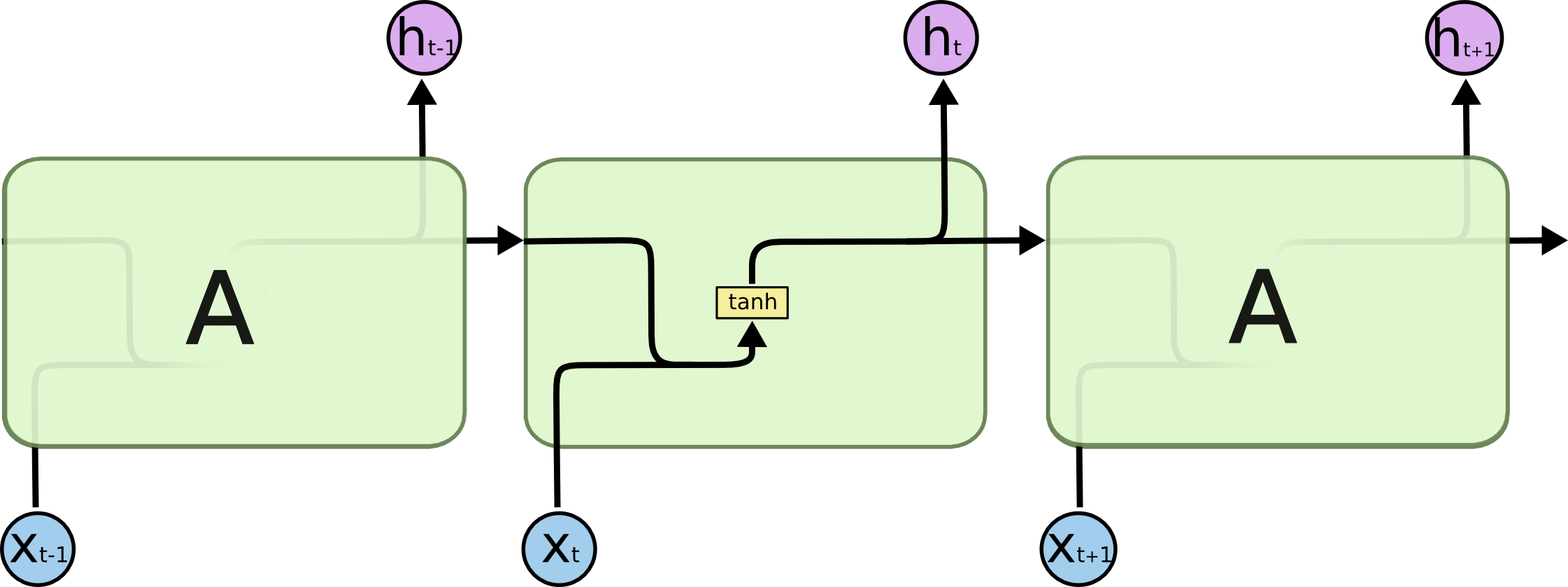
ماژولهای تکرار شونده در شبکههای عصبی بازگشتی استاندارد فقط دارای یک لایه هستند.
شبکههای LSTM نیز چنین ساختار دنباله یا زنجیرهمانندی دارند ولی ماژولِ تکرار شونده ساختار متفاوتی دارد. به جای داشتن تنها یک لایه شبکه عصبی، ۴ لایه دارند که طبق ساختار ویژهای با یکدیگر در تعامل و ارتباط هستند.
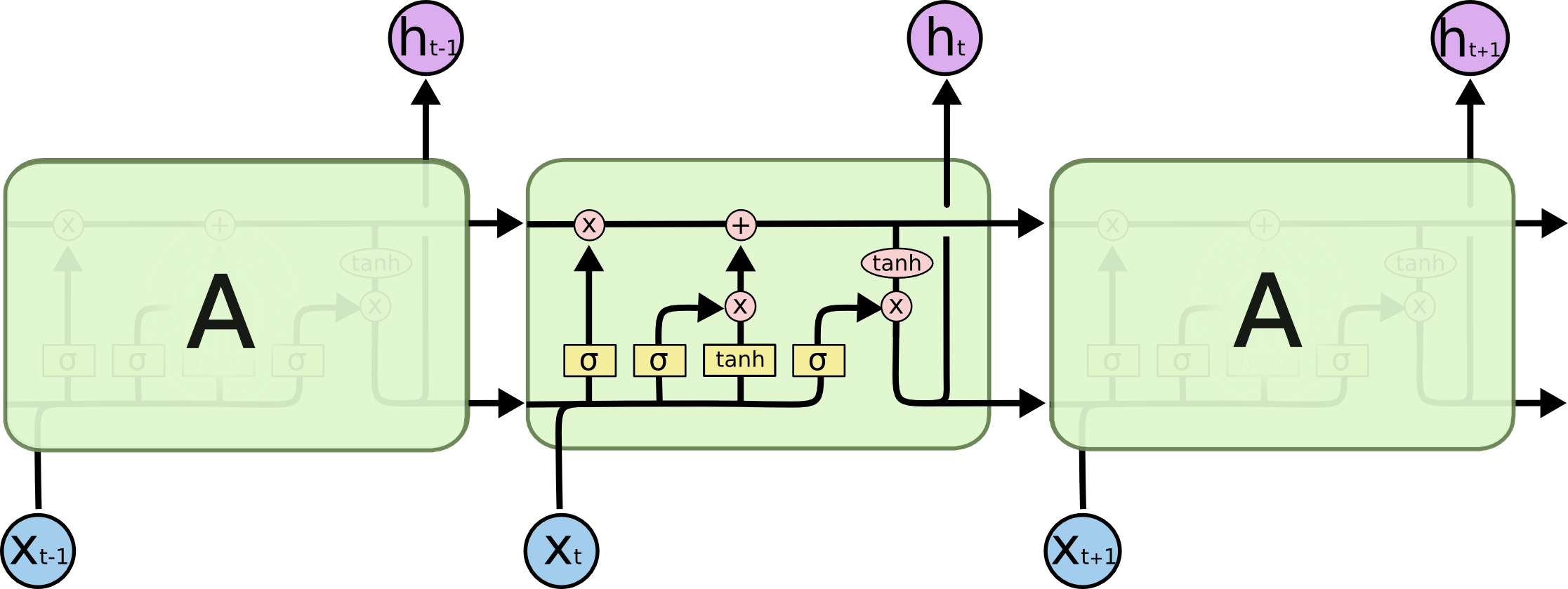
ماژولهای تکرار شونده در LSTMها دارای ۴ لایه که با هم در تعامل هستند است.
نگران جزئیات تصویر نباشید، جلوتر قدم یه قدم ساختار شبکههای LSTM را توضیح خواهیم داد. ابتدا معنی هر کدام از شکل و علامتهایی را که از آنها استفاده خواهیم کرد توضیح می دهیم.

کپی کردن | وصل کردن | بردار انتقال | عملیات نقطه به نقطه | یک لایهی شبکه عصبی
در شکل بالا، هر خط یک بردار را به صورت کامل از خروجی یک گره به ورودی گره دیگر انتقال میدهد. دایرههای صورتی نمایش دهنده عملیاتهای نقطه به نقطه مانند «جمع کردن دو بردار» هستند. مستطیلهای زرد، لایههای شبکههای عصبی هستند که شبکه پارامترهای آنها را یاد میگیرد. خطهایی که با هم ادغام میشوند نشاندهنده الحاق (concatenation) و خطهایی که چند شاخه میشوند نشان دهندهای این موضوع است که محتوای آنها کپی و به بخشهای مختلف ارسال میشود.
ایده اصلیِ پشت LSTMها
عنصر اصلی LSTMها سلول حالت (cell state) است که در حقیقت یک خط افقی است که در بالای شکل قرار دارد.
سلول حالت را میتوان به صورت یک تسمه نقاله تصور کرد که از اول تا آخر دنباله یا همان زنجیره با تعاملات خطیِ جزئی در حرکت است (یعنی ساختار آن بسیار ساده است و تغییرات کمی در آن اتفاق میافتد).
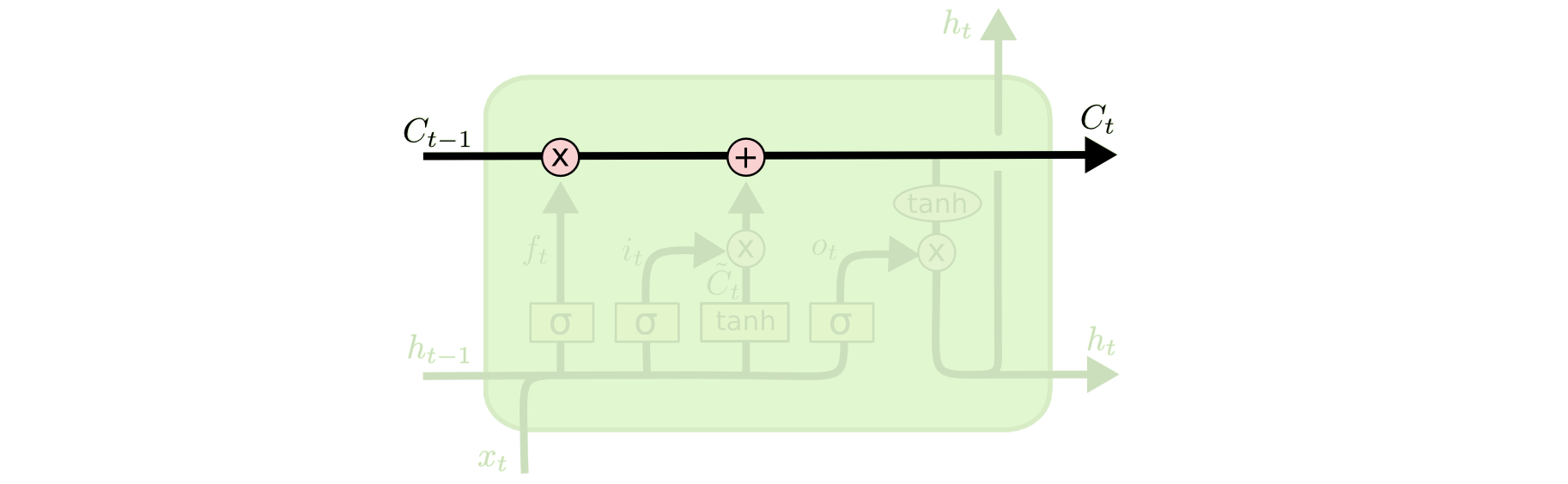
LSTM این توانائی را دارد که اطلاعات جدیدی را به سلول حالت اضافه یا اطلاعات آن را حذف کنید. این کار توسط ساختارهای دقیقی به نام دروازهها (gates) انجام میشود.
دروازهها راهی هستند برای ورود اختیاری اطلاعات. آنها از یک لایه شبکه عصبیِ سیگموید (sigmoid) به همراه یک عملگر ضرب نقطه به نقطه تشکلیل شدهاند.
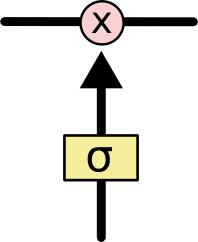
خروجی لایه سیگموید عددی بین صفر و یک است، که نشان میدهد چه مقدار از وروی باید به خروجی ارسال شود. مقدار صفر یعنی هیچ اطلاعاتی نباید به خروجی ارسال شود در حالی که مقدار یک یعنی تمام ورودی به خروجی ارسال شود!
LSTM دارای ۳ دروازه مشابه برای کنترل مقدار سلول حالت است.
بررسی قدم به قدمِ ورود و خروج اطلاعات به LSTM
قدم اول در LSTM تصمیم در مورد اطلاعاتی است که میخواهیم آنها را از سلول حالت پاک کنیم. این تصمیم توسط یک لایه سیگموید به نام «دروازه فراموشی» (forget gate) انجام میشود. این دروازه با توجه به مقادیر ht-1 و xt ، برای هر عدد، مقدار صفر یا یک را در سلول حالتِ Ct-1 به خروجی میبرد. مقدار یک یعنی به صورت کامل مقدار حال حاضرِ سلول حالت (Ct-1) را به Ct ببر و مقدار صفر یعنی به صورت کامل اطلاعات سلول حالت کنونی (Ct-1) را پاک کن و هیچ مقداری از آن را به Ct نبر.
بیاید به مثال قبلیمان که یک مدل زبانیای بود که در آن تلاش داشتیم کلمه بعدی را بر اساس همه کلمههای قبلی حدس بزنیم، برگردیم. در چنین مسألهای، سلول حالت ممکن است دربردارنده جنسیت فاعل کنونی باشد، که با توجه به آن میتوانیم تشخیص دهیم از چه ضمیری باید استفاده کنیم. زمانی که یک فاعل جدید در جمله ظاهر میشود، میبایست جنسیت فاعل قبلی حذف شود.

قدم بعدی این است که تصمیم بگیریم چه اطلاعات جدیدی را میخواهیم در سلول حالت ذخیره کنیم. این تصمیم دو بخشی است. ابتدا یک لایه سیگموید به نام دروازه ورودی (input gate) داریم که تصمیم میگیرد چه مقادیری بهروز خواهند شد. مرحله بعدی یک لایه تانژانت هایپربولیک است که برداری از مقادیر به نام Ct~ میسارد که میتوان آنها را به سلول حالت اضافه کرد. در مرحله بعد، ما این دو مرحله را با هم ترکیب میکنیم تا مقدار سلول حالت را بهروز کنیم.
در مثال مدل زبانیای که پیشتر داشتیم، قصد داریم جنسیت فاعل جدید را به سلول حالت اضافه کنیم تا جایگزین جنسیت فاعل قبلی شود که در مرحله قبلی تصمیم گرفتیم آن را فراموش کنیم.

حال زمان آن فرا رسیده است که سلول حالت قدیمی یعنی Ct-1 را سلول حالت جدید یعنی Ct بهروز کنیم. در مراحل قبلی تصمیم گرفته شد که چه کنیم و در حال حاضر تنها لازم است تصمیماتی را که گرفته شد عملی کنیم.
ما مقدار قبلی سلول حالت را در ft ضرب میکنیم که یعنی فراموش کردن اطلاعاتی که پیشتر تصمیم گرفتیم آنها را فراموش کنیم. سپس it * ~Ct را به آن اضافه میکنیم. در حال حاضر مقادیر جدید سلول حالت با توجه به تصمیماتی که پیشتر گرفته شده بود بدست آمدهاند.
در مثال مدل زبانی، اینجا دقیقاً جائی است که اطلاعاتی که در مورد جنسیت قبلی داشتیم را دور میریزیم و اطلاعات جدید را اضافه میکنیم.

در نهایت باید تصمیم بگیریم قرار است چه اطلاعاتی را به خروجی ببریم. این خروجی با در نظر گرفتن مقدار سلول حالت خواهد بود، ولی از فیلتر مشخصی عبور خواهد کرد. در ابتدا، یک لایه سیگموید داریم که تصمیم میگیرد چه بخشی از سلول حالت قرار است به خروجی برده شود. سپس مقدار سلول حالت (پس از بهروز شدن در مراحل قبلی) را به یک لایه تانژانت هایپر بولیک (تا مقادیر بین ۱- و ۱+ باشند) میدهیم و مقدار آن را در خروجی لایه سیگموید قبلی ضرب میکنیم تا تنها بخشهایی که مد نظرمان است به خروجی برود.
در مثال مدل زبانی، با توجه به اینکه تنها فاعل را دیده، در صورتی که مخواهیم کلمه بعدی را حدس بزنیم، ممکن است بخواهد اطلاعاتی در ارتباط با فعل را به خروجی ببرد. برای مثال ممکن است اینکه فاعل مفرد یا جمع است را به خروجی ببرد، که ما با توجه به آن بدانیم فعل به چه فُرمی خواهد بود.

انواع مختلف LSTMها
چیزی که تا الان توضیح داده شده، یک LSTM عادی است. ولی همه LSTMها به این صورت نیستند. در حقیقت در هر مقالهای که از LSTMها استفاده شده، از نسخههایی از LSTM که اندکی با هم متفاوت هستند استفاده شده است. تفاوت تو این LSTMها خیلی کمه ولی خوبه چند نسخه مختلف دیگه از این LSTMها رو بشناسید که در صورت علاقه میتونید نوشته اصلی به زبان انگلیسی رو مطالعه کنید.
ترجمه این نوشته
آخرش لازم میدونم بگم که این متن با اجازه از نویسنده اصلی یعنی آقای Christopher Olah ترجمه شده.

 محمود
محمود